
Quelle: http://www.schoenleber.org/pascal/pascal2-06.html
Listen
Wiederholung
Normale Variablen werden statisch im Speicher abgelegt . Statische Daten haben den Nachteil, dass man schon während der Programmierzeit über die Anzahl der zu verarbeitenden Daten Bescheid wissen muss.
Es gibt jedoch viele Probleme, die das nicht erlauben. Deswegen gibt es einen speziellen Bereich im Arbeitsspeicher, den Heap (engl.: Haufen), in dem bei Bedarf beliebige Werte abgelegt werden können. Da das während der Laufzeit passiert, kann diesen Werten kein (Variablen-)Name zugewiesen werden; man richtet sich deswegen einen "Merkzettel" ein, einen Wert, der auf die entsprechende Adresse im Heap "zeigt", einen sogenannten Zeiger . Er ersetzt den Variablennamen. Solche Daten können genauso schnell weggeräumt werden, wie sie angelegt wurden.
Zeiger werden jedoch zu einem besonderen Zweck eingesetzt. Die erlauben, unterschiedliche Objekte so zu verknüpfen, dass Strukturen entstehen, mit denen man gerne arbeitet:
Diese Listen sind dynamisch, d.h. im Gegensatz zum "Array", dessen Größe schon vor der Laufzeit des Programms festgelegt werden muss, ist es bei einer verketteten Liste auch während der Laufzeit eines Programms völlig offen, wie viel Elemente sie enthalten darf.
Um das zu erreichen, muss bei Bedarf für ein neu einzugebendes Element im System Platz angefordert werden. Die Verkettung der einzelnen Elemente wird dadurch erreicht, dass man dem letzten Element mitteilt, wo das nächste steht. Das Ganze kann man dann mit einer sequentiellen Datei vergleichen, nur dass die "Datei" nicht auf der Platte, sondern im Arbeitsspeicher (Adressraum der Hardware) steht.
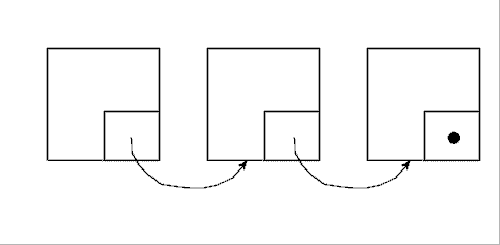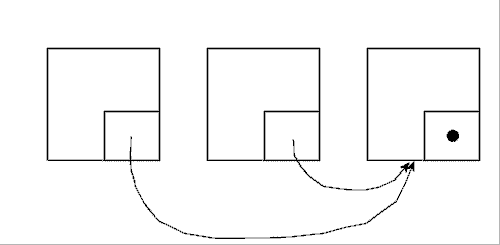
Funktionsweise des Verkettungsmechanismus:
Elemente werden links angefügt, bestehende werden nach rechts geschoben.
In Schritt 1 wird ein Element vom System angefordert. Das Element wird durch den Kasten dargestellt. Es enthält die Daten. Der kleine Kasten mit dem Punkt, das ist der Teil, der uns hier interessiert. Denn hier wird gleich die Adresse des nächsten Elements hineingeschrieben, dargestellt durch einen Pfeil.
In Schritt 2 ist das zweite Element angefordert worden. Diesem wurde die Adresse des ersten Elementes beigegeben, damit die Liste verkettet werden kann. So kann man sich nun von Element Nr. 2 nach Element Nr. 1 "hangeln" (nicht umgekehrt!).
Im 3. Schritt ist das dritte Element angefordert und in die schon bestehende Liste eingefügt, sprich angehängt, worden.
Wenn man die fertige Liste betrachtet, dann merkt man zweierlei:
Zu Punkt eins: Den Anfangszeiger wurde unterschlagen; er wird hiermit nachgereicht und der Punkt erklärt:
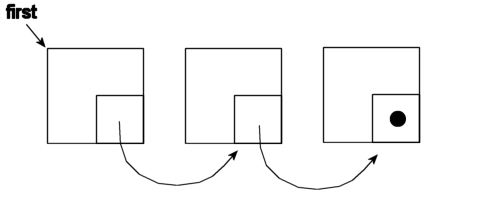
Da das "erste" (zuerst angelegte) Element auf kein weiteres zeigt, kann hier keine echte Adresse stehen. Deswegen gibt es auch für diesen "Zeigertyp" ein neutrales Element. Es heißt NIL und zeigt auf kein anderes Element. Dem System zeigt NIL an, dass die Kette hier zu Ende ist. Eine Variable vom Typ Zeiger kann auf diesen Wert abgefragt werden. Der "dicke" Punkt in der Ecke des "letzten" Elementes ist der besondere Wert.
Der "Anfangszeiger" (er heißt oft "first") muss natürlich mit jedem neu angeforderten Element verändert werden! Da das der Programmierer sollte, muss man sich diesen Schritt genau einprägen!
Zu Punkt zwei: Man kann eine einfach verkettet Liste auch anders organisieren, aber das hier ist die einfachste Form. Die Einfachheit wird jedoch mit der Eigenschaft bezahlt, dass das zuletzt angefügte Element beim Auslesen der (sequentiellen) Liste als erstes Element wiedergefunden wird. Die Reihenfolge wird umgedreht. Das lässt sich aber kompensieren.
Um eine Variable vom Typ Pointer in einem Record zu benutzen, ist "ein wenig" Vorarbeit notwendig.
TYPE link = ^person; person = RECORD name : STRING [40]; next : link; END; VAR p,first : link;
Wir müssen vorher nur noch zwei Dinge klären:
new (<zeigervariable>)
new (p)
Um dabei den Anschluss an die Liste nicht zu verlieren, muss der Anfangszeiger natürlich diesen neuen Wert erhalten. Der alte Wert des Anfangszeigers muss vorher der Zeigervariablen des neuen Records zugewiesen werden, damit das neue Element mit der Liste verbunden wird.
Üblicherweise werden, wenn man keine spezielleren Bezeichnungen benötigt, der Listenzeiger "p" und der Anfangszeiger "first" genannt.
Zur Antwort auf die zweite Frage: Wie man gleich im Beispiel sehen wird, gibt es keine extra Variable, die den Record repräsentieren würde. Es ist überflüssig, man weiß ja, wo der Record im Speicher steht, nämlich ab der Adresse, die in "p" steht. Dadurch brauchen wir keinen Variablennamen. Also sprechen wir die Datenfelder durch die Zeigervariable fast wie gewohnt an. Der Unterschied ist nur, dass man dem System mitteilen muss, dass man nicht ein Datenfeld des Zeigers haben möchte, sondern ein Datenfeld des Records, auf das der Pointer zeigt! Das geschieht dann folgendermaßen:
<zeigervariable>^.<datenfeldbezeichner>
p^.name
Wenden wir das bisher Gesagte im Beispiel an:
PROGRAM zeiger_liste; USES crt;
TYPE link = ^liste;
liste = RECORD
name : STRING [80];
next : link;
END;
VAR p,first : link;
index : integer;
n : STRING [80];
BEGIN
clrscr; { Das spaetere letzte Element der Liste zeigt auf }
{ keinen weiteren Datensatz. }
first := NIL;
FOR index := 1 TO 10 DO
BEGIN { Pointerelemente einlesen }
write ('->');
readln (n);
{ Anfordern eines neuen Records }
new (p);
{ Zuweisen des Recorddatenfeldes }
p^.name := n;
{ Der neue Record bekommt die Adresse des }
{ letzten Records, die ja in "first" noch }
{ steht. }
p^.next := first;
{ Aktualisieren des Anfangszeigers }
first := p
END;
{ Vorbereitung der Ausgabe: Zeiger "p" wird auf }
{ das "erste" Element der Liste gesetzt }
p := first;
WHILE (p <> NIL) DO
BEGIN
{ Pointerelemente ausgeben }
write (p^.name:4);
{ Setzen des Zeigers auf den naechsten Record }
p := p^.next
END;
READLN;
END.Generierung der Liste: Dabei ist die Form der Schleife unwichtig. Hier ist es eine FOR-Schleife. Auch die Eingabeform ist unwichtig. Genausogut könnte man die Eingabe auch aus einer Datei vornehmen.
Ausgabe der Liste: Für die Ausgabe bzw. für das lineare Durchsuchen sind also wesentlich weniger Schritte notwendig. Wichtig ist die Bedingung in der WHILE-Schleife, die das Ende der Liste über den Wert NIL ermittelt.
Schwierig wird das Ganze, wenn ein Datensatz aus der Liste entfernt oder eingefügt werden soll.
Schauen wir uns wieder an, was bim Einfügen und Löschen passiert.
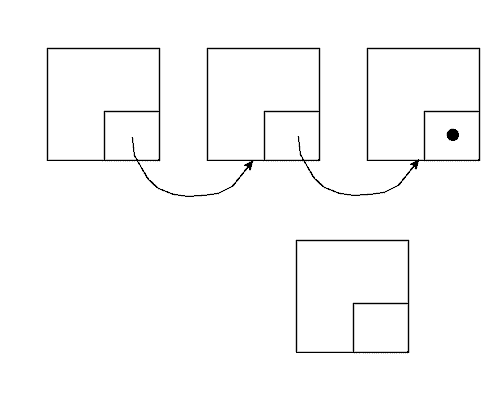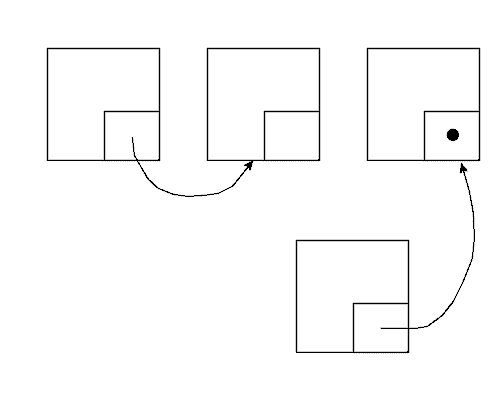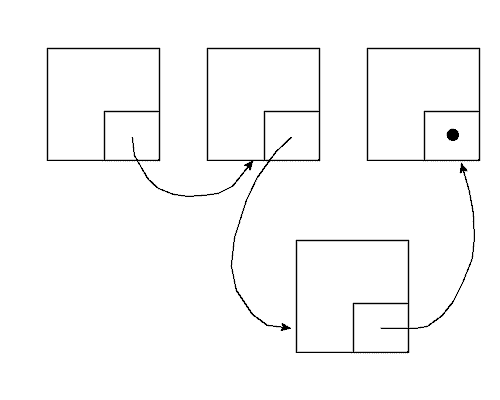
Dabei müssen folgende Schritte ausgeführt werden:
Folgende Schritte sind hier nötig:
Doch dafür kurz ein Wort über die
Zeigerverwaltung von Turbo PASCAL. Die Datensätze, auf die die Zeiger
verweisen, werden in einem gesonderten Speicherbereich, genannt "Heap",
abgelegt. Man kann ihn sich ungefähr so vorstellen:
| -->p_1 |
Datensatz 1 |
| -->p_2 |
Datensatz 2 |
| -->p_3 |
Datensatz 3 |
... |
|
| -->p_n |
Datensatz n |
[Heapgrenze] |
[freier Platz] ... ... |
| [Heap] | |
Wenn man jetzt einen Datensatz aus der verketteten Liste herausnimmt, dann will man auch dessen Speicherplatz wieder als frei kennzeichnen, d.h. für die Prozedur new wieder zur Verfügung stellen.
dispose (<zeigervariable>)
Nach
dispose (p2)
Es gibt in Turbo PASCAL noch eine weitere Methode:
Mit der Prozedur mark markiert man zunächst die Position eines bestimmten Datensatzes, indem man einfach den aktuellen Zeiger in einer gesonderten Zeigervariablen "markiert" (sichert). Durch die spätere Verwendung von release in Bezug auf diesen Zeiger wird der komplette Heap ab dieser Position gelöscht.